Note
Click here to download the full example code
Plot performance curves
This example illustrates how to use the
imbens.visualizer module to visualize or
compare imbens.ensemble classifier(s).
This example uses:
# Authors: Zhining Liu <zhining.liu@outlook.com>
# License: MIT
print(__doc__)
from time import time
# Import imbalanced-ensemble
import imbens
# Import utilities from sklearn
import sklearn
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
RANDOM_STATE = 42
# sphinx_gallery_thumbnail_number = 4
Prepare data
Make a toy 3-class imbalanced classification task.
# make dataset
X, y = make_classification(n_classes=3, class_sep=2,
weights=[0.1, 0.3, 0.6], n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=2, n_samples=2000, random_state=0)
# train valid split
X_train, X_valid, y_train, y_valid = train_test_split(
X, y, test_size=0.5, stratify=y, random_state=RANDOM_STATE)
Train ensemble classifiers
4 different ensemble classifiers are used.
init_kwargs = {'n_estimators': 50, 'random_state': RANDOM_STATE}
fit_kwargs = {'X': X_train, 'y': y_train}
# imbens.ensemble classifiers
ensemble_dict = {
'SPE': imbens.ensemble.SelfPacedEnsembleClassifier(**init_kwargs),
'EasyEns': imbens.ensemble.EasyEnsembleClassifier(**init_kwargs),
'BalanceForest': imbens.ensemble.BalancedRandomForestClassifier(**init_kwargs),
'SMOTEBagging': imbens.ensemble.SMOTEBaggingClassifier(**init_kwargs),
}
# Train all ensemble classifiers, store the results in fitted_ensembles
fitted_ensembles = {}
for clf_name, clf in ensemble_dict.items():
start_time = time()
clf.fit(**fit_kwargs)
fit_time = time() - start_time
fitted_ensembles[clf_name] = clf
print ('Training {:^30s} | Time used: {:.3f}s'.format(clf.__name__, fit_time))
Training SelfPacedEnsembleClassifier | Time used: 0.140s
Training EasyEnsembleClassifier | Time used: 0.664s
Training BalancedRandomForestClassifier | Time used: 0.081s
Training SMOTEBaggingClassifier | Time used: 1.881s
Fit an ImbalancedEnsembleVisualizer
The visualizer fits on a dictionary like {…, ensemble_name: ensemble_classifier, …}
The keys should be strings corresponding to ensemble names.
The values should be fitted imbalance_ensemble.ensemble or sklearn.ensemble estimator objects.
# Initialize visualizer
visualizer = imbens.visualizer.ImbalancedEnsembleVisualizer(
eval_datasets = {
'training' : (X_train, y_train),
'validation' : (X_valid, y_valid),
},
eval_metrics = {
'acc': (sklearn.metrics.accuracy_score, {}),
'balanced_acc': (sklearn.metrics.balanced_accuracy_score, {}),
'weighted_f1': (sklearn.metrics.f1_score, {'average':'weighted'}),
},
)
# Fit visualizer
visualizer.fit(fitted_ensembles)
0%| | 0/50 [00:00<?, ?it/s]
Visualizer evaluating model SPE on dataset training :: 0%| | 0/50 [00:00<?, ?it/s]
Visualizer evaluating model SPE on dataset training :: 100%|################################################################################################################################################################################################| 50/50 [00:00<00:00, 2559.69it/s]
0%| | 0/50 [00:00<?, ?it/s]
Visualizer evaluating model SPE on dataset validation :: 0%| | 0/50 [00:00<?, ?it/s]
Visualizer evaluating model SPE on dataset validation :: 100%|################################################################################################################################################################################################| 50/50 [00:00<00:00, 2591.76it/s]
0%| | 0/50 [00:00<?, ?it/s]
Visualizer evaluating model EasyEns on dataset training :: 0%| | 0/50 [00:00<?, ?it/s]
Visualizer evaluating model EasyEns on dataset training :: 80%|##########################################################################################################################################################4 | 40/50 [00:00<00:00, 307.46it/s]
Visualizer evaluating model EasyEns on dataset training :: 100%|#################################################################################################################################################################################################| 50/50 [00:00<00:00, 260.03it/s]
0%| | 0/50 [00:00<?, ?it/s]
Visualizer evaluating model EasyEns on dataset validation :: 0%| | 0/50 [00:00<?, ?it/s]
Visualizer evaluating model EasyEns on dataset validation :: 80%|##########################################################################################################################################################4 | 40/50 [00:00<00:00, 311.84it/s]
Visualizer evaluating model EasyEns on dataset validation :: 100%|#################################################################################################################################################################################################| 50/50 [00:00<00:00, 263.83it/s]
0%| | 0/50 [00:00<?, ?it/s]
Visualizer evaluating model BalanceForest on dataset training :: 0%| | 0/50 [00:00<?, ?it/s]
Visualizer evaluating model BalanceForest on dataset training :: 100%|################################################################################################################################################################################################| 50/50 [00:00<00:00, 2858.67it/s]
0%| | 0/50 [00:00<?, ?it/s]
Visualizer evaluating model BalanceForest on dataset validation :: 0%| | 0/50 [00:00<?, ?it/s]
Visualizer evaluating model BalanceForest on dataset validation :: 100%|################################################################################################################################################################################################| 50/50 [00:00<00:00, 2842.52it/s]
0%| | 0/50 [00:00<?, ?it/s]
Visualizer evaluating model SMOTEBagging on dataset training :: 0%| | 0/50 [00:00<?, ?it/s]
Visualizer evaluating model SMOTEBagging on dataset training :: 100%|################################################################################################################################################################################################| 50/50 [00:00<00:00, 2465.73it/s]
0%| | 0/50 [00:00<?, ?it/s]
Visualizer evaluating model SMOTEBagging on dataset validation :: 0%| | 0/50 [00:00<?, ?it/s]
Visualizer evaluating model SMOTEBagging on dataset validation :: 100%|################################################################################################################################################################################################| 50/50 [00:00<00:00, 2432.50it/s]
Visualizer computing confusion matrices........ Finished!
<imbens.visualizer.visualizer.ImbalancedEnsembleVisualizer object at 0x00000247624782B0>
Plot performance curve
Performance w.r.t. number of base estimators
fig, axes = visualizer.performance_lineplot()
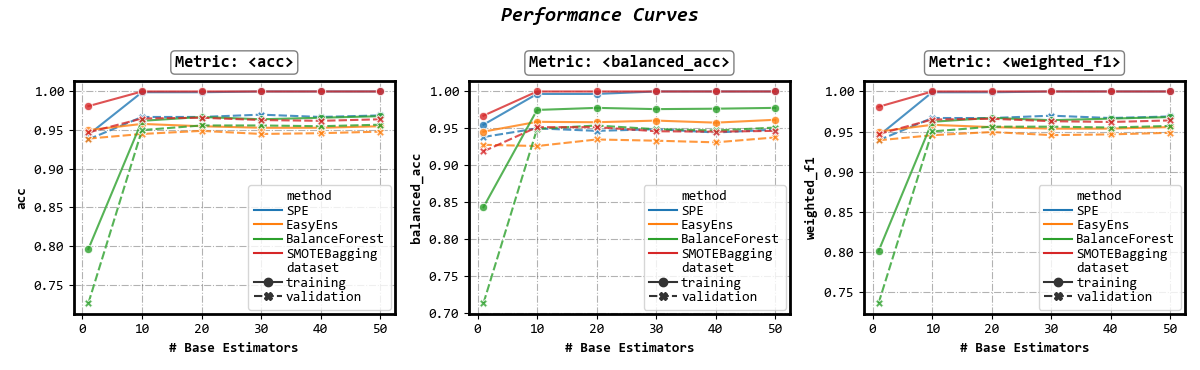
Set x-axis
(parameter n_samples_as_x_axis: bool)
Performance w.r.t. number of training samples
fig, axes = visualizer.performance_lineplot(
n_samples_as_x_axis=True,
)
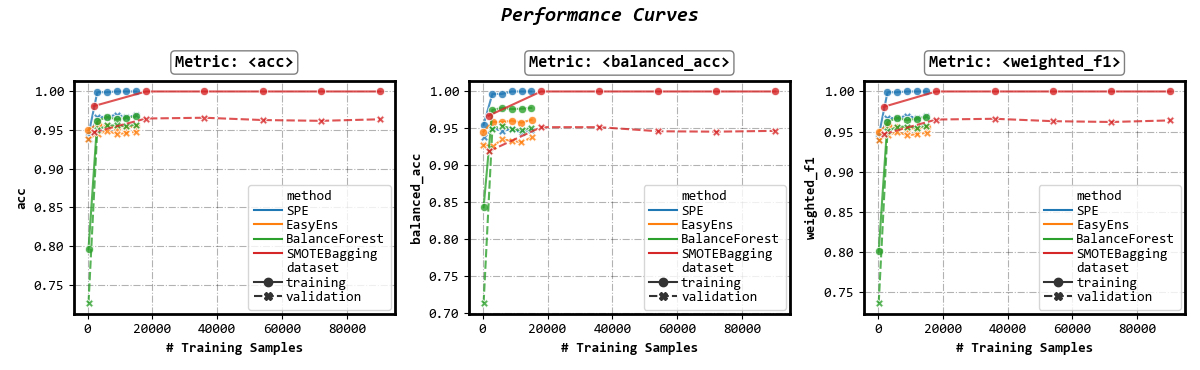
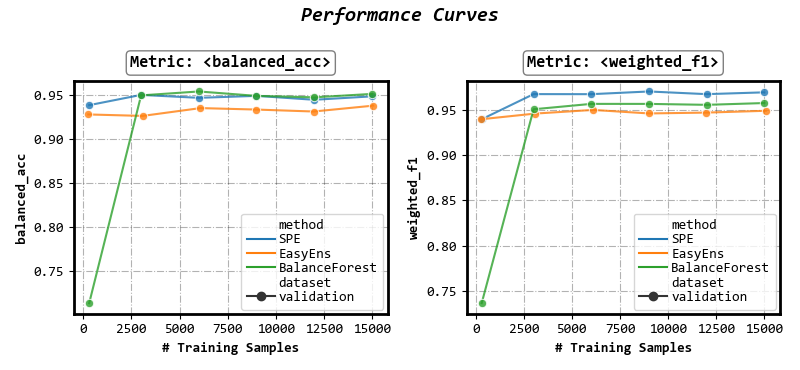
Select results for visualization
(parameter on_ensembles: list of ensemble name, on_datasets: list of dataset name, on_metrics: list of metric name)
Select: method (‘SPE’, ‘SMOTEBagging’), data (‘validation’), metric (‘balanced_acc’, ‘weighted_f1’)
fig, axes = visualizer.performance_lineplot(
on_ensembles=['SPE', 'EasyEns', 'BalanceForest'],
on_datasets=['validation'],
on_metrics=['balanced_acc', 'weighted_f1'],
n_samples_as_x_axis=True,
)
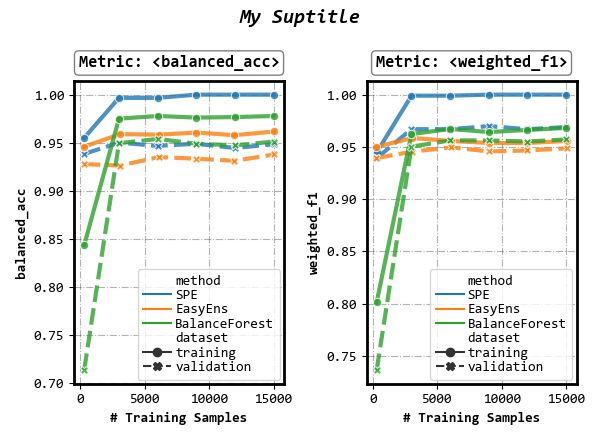
Customize visual appearance
(parameter sub_figsize: tuple, sup_title: bool or string, kwargs of seaborn.lineplot())
fig, axes = visualizer.performance_lineplot(
on_ensembles=['SPE', 'EasyEns', 'BalanceForest'],
on_datasets=['training', 'validation'],
on_metrics=['balanced_acc', 'weighted_f1'],
n_samples_as_x_axis=True,
# Customize visual appearance
sub_figsize=(3, 4),
sup_title='My Suptitle',
# arguments pass down to seaborn.lineplot()
linewidth=3,
markers=True,
alpha=0.8,
)
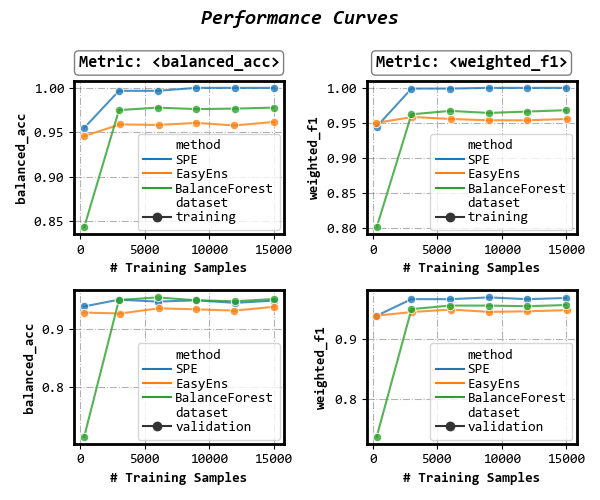
Group results
(parameter split_by: list of {‘method’, ‘dataset’})
Group results by dataset
fig, axes = visualizer.performance_lineplot(
on_ensembles=['SPE', 'EasyEns', 'BalanceForest'],
on_datasets=['training', 'validation'],
on_metrics=['balanced_acc', 'weighted_f1'],
n_samples_as_x_axis=True,
sub_figsize=(3, 2.3),
split_by=['dataset'], # Group results by dataset
)
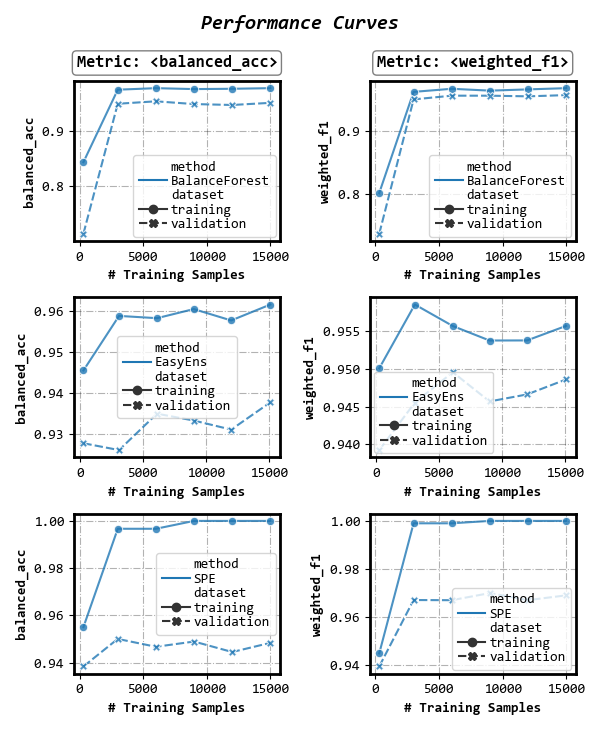
Group results by method
fig, axes = visualizer.performance_lineplot(
on_ensembles=['SPE', 'EasyEns', 'BalanceForest'],
on_datasets=['training', 'validation'],
on_metrics=['balanced_acc', 'weighted_f1'],
n_samples_as_x_axis=True,
sub_figsize=(3, 2.3),
split_by=['method'], # Group results by method
)
Total running time of the script: ( 0 minutes 4.654 seconds)