Note
Click here to download the full example code
Make a dataset class-imbalanced
An illustration of the make_imbalance() function to
create an imbalanced dataset from a balanced dataset. We show the ability of
make_imbalance() of dealing with Pandas DataFrame.
# Adapted from imbalanced-learn
# Authors: Dayvid Oliveira
# Christos Aridas
# Guillaume Lemaitre
# Zhining Liu <zhining.liu@outlook.com>
# License: MIT
print(__doc__)
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context("poster")
Generate the dataset
First, we will generate a dataset and convert it to a
DataFrame with arbitrary column names. We will plot the
original dataset.
import pandas as pd
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=200, shuffle=True, noise=0.25, random_state=10)
X = pd.DataFrame(X, columns=["feature 1", "feature 2"])
fig = plt.figure(figsize=(6, 5))
ax = sns.scatterplot(
data=X,
x="feature 1",
y="feature 2",
hue=y,
style=y,
)
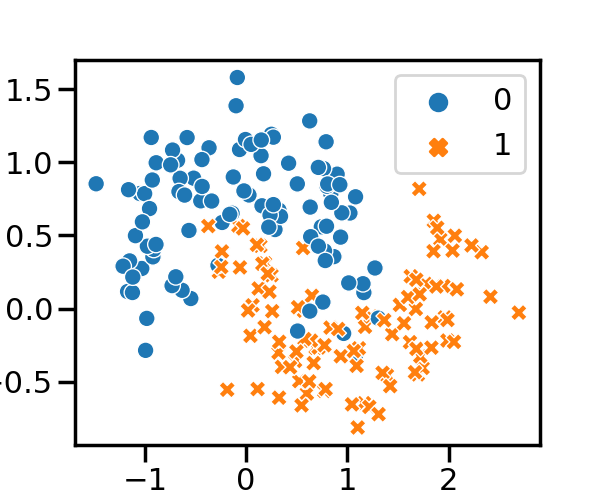
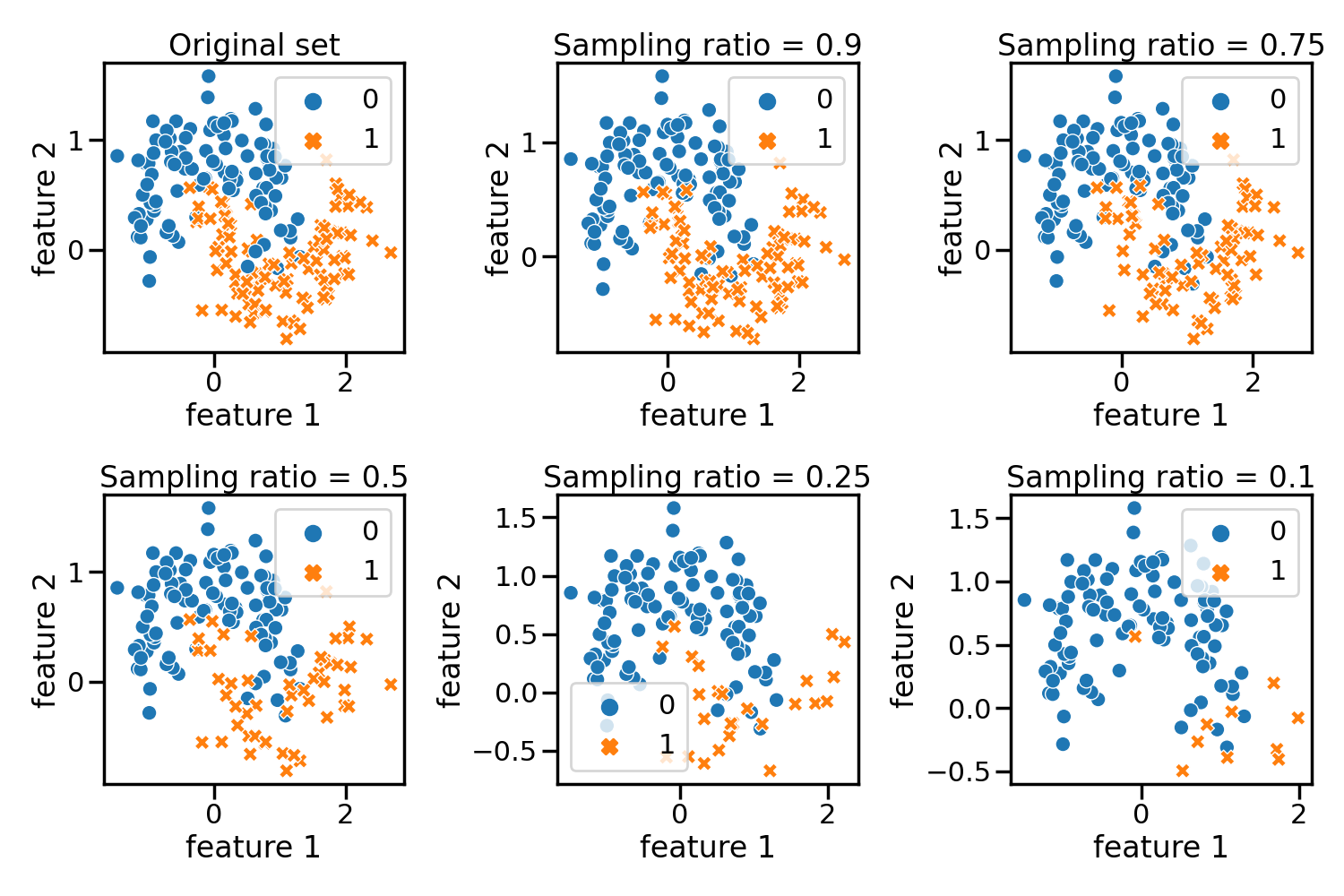
Make a dataset imbalanced
Now, we will show the helpers make_imbalance()
that is useful to random select a subset of samples. It will impact the
class distribution as specified by the parameters.
from collections import Counter
def ratio_func(y, multiplier, minority_class):
target_stats = Counter(y)
return {minority_class: int(multiplier * target_stats[minority_class])}
from imbens.datasets import make_imbalance
fig, axs = plt.subplots(nrows=2, ncols=3, figsize=(15, 10))
sns.scatterplot(
data=X,
x="feature 1",
y="feature 2",
hue=y,
style=y,
ax=axs[0, 0],
)
axs[0, 0].set_title("Original set")
multipliers = [0.9, 0.75, 0.5, 0.25, 0.1]
for ax, multiplier in zip(axs.ravel()[1:], multipliers):
X_resampled, y_resampled = make_imbalance(
X,
y,
sampling_strategy=ratio_func,
**{"multiplier": multiplier, "minority_class": 1},
)
sns.scatterplot(
data=X_resampled,
x="feature 1",
y="feature 2",
hue=y_resampled,
style=y_resampled,
ax=ax,
)
ax.set_title(f"Sampling ratio = {multiplier}")
plt.tight_layout()
plt.show()
Total running time of the script: ( 0 minutes 0.315 seconds)