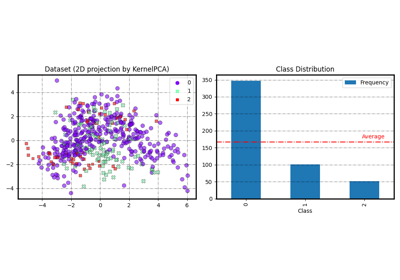
generate_imbalance_data
- imbens.datasets.generate_imbalance_data(n_samples=200, weights=[0.9, 0.1], test_size=0.5, random_state=None, kwargs={})[source]
Generate a random n-classes imbalanced classification problem.
Returns the training and test data and labels.
- Parameters:
- n_samplesint, default=100
The number of samples.
- weightsarray-like of shape (n_classes,), default=[.9,.1]
The proportions of samples assigned to each class, i.e., it determines the imbalance ratio between classes. If None, then classes are balanced. Note that the number of class will be automatically set to the length of weights.
- test_sizefloat or int, default=None
If float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the test split. If int, represents the absolute number of test samples.
- random_stateint, RandomState instance or None, default=None
If int, random_state is the seed used by the random number generator; If RandomState instance, random_state is the random number generator; If None, the random number generator is the RandomState instance used by np.random.
- kwargsdict
Dictionary of additional keyword arguments to pass to
sklearn.datasets.make_classification. Please see details here.
- Returns:
- X_train{ndarray, dataframe} of shape (n_samples*(1-test_size), n_features)
The array containing the imbalanced training data.
- X_test{ndarray, dataframe} of shape (n_samples*test_size, n_features)
The array containing the imbalanced test data.
- y_trainndarray of shape (n_samples*(1-test_size))
The corresponding label of X_train.
- y_testndarray of shape (n_samples*test_size)
The corresponding label of X_test.